 En
EnКак работает BDE, или архитектура BDE и его особенности при работе с SQL-серверами
Кузьменко Дмитрий, www.ibase.ru, 25.08.2000 (исправления – 14.12.2000, 17.08.2001).
Этот материал основан на изучении документации и справочных материалов по BDE и на собственном опыте. На самом деле информация из этого документа частично появлялась и раньше как в FAQ Borland так и в материалах других авторов (в частности Epsylon Technologies). Однако до сих пор большое количество разработчиков используют BDE. Но в последнее время все больше людей работают с SQL-серверами, и более популярными становятся компоненты прямого доступа – IBObjects/FreeIBComponents/IBExpress, Direct Oracle Access и другие. Кроме того, BDE не поддерживается на Linux (в Kylix) и дальше развиваться не будет – The Future of the Borland Database Engine (BDE) and SQL Links (by John Kaster). В Delphi 6 наряду с BDE и в Kylix (Delphi и C++Builder для Linix) используется другая библиотека – dbExpress, которая и предлагается Borland в качестве замены BDE. Поэтому, чтобы поставить жирную точку (или крест, как хотите) на BDE, я и решил написать этот документ.
В большей степени этот текст напоминает то, что я читал на курсах по Delphi и разработке баз данных 3-4 года назад. Привет вам, курсанты! Можете прочитать этот документ хотя бы для того, чтобы освежить память.
Введение
Для начала вернемся лет на 10 назад. В те времена на компьютерах властвовали настольные СУБД – dBase, Paradox, FoxPro, Clipper и т.п. SQL-сервера в основном работали на мэйнфреймах. Среди форматов настольных СУБД был полный разнобой, и например, хотя Clipper, FoxPro и dBase работали с форматом DBF, использовать таблицы друг друга они фактически не могли из-за мелких, но существенных различий. Обмениваться данными в те времена между разными СУБД можно было разве что при помощи импорта-экспорта. Многие компании понимали, что так дальше продолжаться не может. Некоторые встраивали в свои продукты несколько "движков", но это приводило к распуханию продукта, да и чаще всего пользователи работали только с одним форматом данных, а не несколькими одновременно.В 1990-м году Borland приобрел компанию Ashton-Tate, а вместе с ней и dBase (и Interbase). Таким образом у Borland появилось две настольные СУБД, с совершенно разными форматами – dBase и Paradox. Понятно, что для дальнейшего развития этих продуктов усилия по развитию форматов данных и работы с ними фактически удваивались. И в частности поэтому было принято решение создать некое универсальное ядро доступа к данным, которое могло бы работать с несколькими форматами данных единым образом. Созданию такого ядра также способствовало появление Windows, а следовательно и разделяемых библиотек – DLL. Можно было выпускать несколько продуктов, используя одни и те же dll доступа к данным. Это вполне соответствовало объектно-ориентированной концепции разработки ПО, которая не только использовалась в Turbo Pascal и в Turbo C++, но и при разработке собственных приложений Borland, таких как dBase, Paradox и Quattro (все для Windows).
Примечание. Дальнейшая информация по датам взята из документа, подзаголовок "Evolution of BDE/IDAPI Technology: 1990 - 94".
Технология была названа Open Database Application Programming Interface – ODAPI, и впервые была использована в Quattro Pro 1.0 for Windows в сентябре 1992 года. В январе 1993-го эта же версия ODAPI 1.0 была использована в Paradox 1.0 for Windows, а затем и в dBase 1.0 for Windows. ODAPI пока поддерживал только форматы dBase и Paradox, и мог выполнять запросы к обоим форматам при помощи механизма Query By Example (QBE), пришедшего из Paradox for DOS.Справка. Драйверы ODBC 1.0 от Microsoft впервые появились в августе 1993 года. Информация из MSDN.
Всего через полгода, в сентябре 1993, ODAPI 1.1 уже поддерживала работу с SQL-серверами Interbase, Oracle, Sybase и Microsoft.Версия 2.0 была переименована в IDAPI (слово Open было заменено на Integrated), и работами по расширению и стандартизации этого интерфейса уже занимался не только Borland, а целый комитет с IBM, Novell и Wordperfect включительно. В этой версии появился Local SQL – ядро для выполнения запросов SQL к локальным форматам данных, и IDAPtor – механизм для подключения ODBC-драйверов к IDAPI.
Последняя 16-ти разрядная версия IDAPI 2.5 использовалась в Delphi 1. Далее, начиная с 3.0 (12 января 1996 года в составе Paradox 5.0 for Windows), пошли 32-разрядные версии. Собственно, на этом развитие функциональности BDE закончилось. Добавлялись новые драйверы для доступа к SQL-серверам DB2, Informix, в BDE 3.5 появились кэшированные обновления (CachedUpdates), появился драйвер FoxPro и сопряжение с DAO, но все это происходило на протяжении достаточно длительного срока – с 1996 по 2000.
С одной стороны, функциональность BDE можно назвать даже избыточной. С другой стороны повлияла конкуренция со стороны Microsoft, стандарта ODBC. Собственно, по функциональности ODBC является подмножеством BDE, но Microsoft в те годы предпринимала очень активные действия по продвижению ODBC, и главным в этом был выпуск ODBC SDK, с помощью которого любая фирма могла разработать собственный ODBC-драйвер (надо сказать, что в те годы их было огромное количество, причем большинство было весьма низкого качества и невысокой производительности). А BDE был более "закрытым". Например, BDE SDK так и не увидел свет, и был доступен разве что избранным (я оказался в их числе, и надо сказать, что качество BDE SDK и удобство написания драйверов было на высоте). С третьей стороны, к этому времени WordPerfect был куплен Novell, Paradox также был продан Novell, а затем Corel, а IBM похоже просто потеряла к IDAPI интерес.
Короче, комитет IDAPI распался, а Microsoft задавил конкуренцией.
Несмотря на перечисленные негативные моменты, BDE активно использовался не только самим Borland, но и многими другими фирмами. Это Novell (продукт InForms), ReportSmith (впоследствии купленный и проданный Borland), CrystalReports (вплоть до версии 5.0 использовал BDE) и так далее.
Дополнение текущего момента
14 мая 2002 года была опубликована статья "Будущее BDE и SQL Links", из которой явно следует, что никакого будущего у BDE нет. Т. е. дальше он развиваться не будет, а на смену ему пришел dbExpress (сейчас, в начале 2004 года – Borland Data Provider для .Net и т. п.).В частности, BDE хоть и поддерживает третий диалект для InterBase 6 и выше, однако только частично. Т. е. основное нововведение третьего диалекта в виде numeric(x,y), использующего внутренний int64 вместо double precision, не поддерживается, и такой столбец будет выгдядеть в BDE как тип Bytes.
Архитектура
Увлекшись историей я немного пропустил, зачем все это (BDE) делалось. Частичная цель упоминалась выше – предоставить универсальное ядро доступа к локальным форматам данных. Основная – обеспечить прозрачную работу приложений как с локальными форматами, так и с SQL-серверами. Как сейчас помню, что именно удобство при работе с SQL-серверами рекламировалось как основное. Однако в последние 2-3 года именно эта возможность вызывала наибольшее количество нареканий. Давайте рассмотрим архитектуру BDE.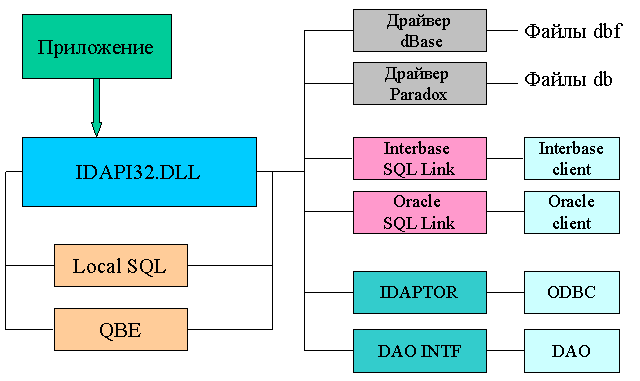
Основная работа с BDE производится посредством внешнего интерфейса IDAPI (IDAPI32.DLL). Формат данных выбирается в псевдониме (alias) соединения, и в принципе дальше работа с разными форматами ничем не отличается. В том числе и неважно, как работает приложение с BDE – через компоненты VCL DB, которые используют функции BDE, или напрямую (все равно компоненты используют те же функции BDE).
Дальше функции IDAPI транслируют вызовы в функции соответствующего драйвера. Если это драйвер локального формата (dBase, Paradox, FoxPro), то драйвер формата сам работает с соответствующими файлами (таблицами и индексами). Если это SQL Link, то вызовы транслируются в вызовы функций API клиентской части конкретного SQL-сервера. Для каждого сервера SQL Link свой.
IDAPTOR (соединитель с ODBC) и интерфейс к DAO работает точно также как и SQL Link, т. е. просто транслирует вызовы BDE в вызовы ODBC или DAO, непосредственно к формату не имея никакого отношения.
Если посмотреть на файлы BDE, то можно подробно рассмотреть его составные части:
- IDAPI32.DLL – основной интерфейс
- BLW32.DLL, BANTAM.DLL – языковые функции
- *.BTL – файлы с языковыми кодировками.
- IDBAT32.DLL – операции пакетного копирования данных
- IDDR32.DLL – модуль работы с Data Repository
- IDASCI32.DLL – драйвер для работы с текстовым форматом
- IDDAO32.DLL – драйвер трансляции вызовов к DAO
- IDODBC32.DLL – драйвер трансляции вызовов к ODBC
- IDPDX32.DLL – драйвер для работы с форматом Paradox
- IDDBAS32.DLL – драйвер для работы с форматом dBase и FoxPro
- IDQBE32.DLL – ядро обработки запросов QBE
- IDSQL32.DLL – ядро обработки запросов SQL
- SQLINT32.DLL – SQLLink-драйвер трансляции вызовов к Interbase API
- SQLORA32.DLL – SQLLink-драйвер трансляции вызовов к Oracle Call Level Interface
- SQL*32.DLL – другие SQLLink-драйверы
Таким образом, при установке BDE "лишние" файлы можно без проблем выкинуть.
Также, надеюсь, понятно, почему BDE "не работает" с SQL-сервером, если не установлена клиентская часть этого сервера (то же самое по отношению к DAO – без дистрибутива DAO BDE не будет работать с файлами MS Access). Вообще клиентские части SQL-серверов несовместимы между собой абсолютно. Поэтому невозможно написать универсальный SQL Link.
Данный рисунок и список файлов, возможно, развеет популярный миф о том, что Delphi хорошо приспособлена для работы с Interbase. Как видите, Interbase для Delphi столь же равноправен, как скажем, Oracle или любой ODBC-драйвер. В отличие от продуктов Microsoft в BDE нет никаких "обходных" функций для работы со своими форматами, т. е. работа с IB ведется только через SQL Link (без sqlint32.dll BDE вообще не знает, что такое Interbase).
Отдельное место в архитектуре BDE и среди упомянутых файлов занимают Local SQL и QBE Engine. Эти механизмы запросов будут рассмотрены чуть дальше.
TTable и TQuery
TTable и TQuery являются основными компонентами, используемыми при программировании приложений баз данных (TStoredProc не в счет, и без него можно прекрасно обойтись, вызывая процедуры через select или execute в компоненте TQuery). TTable предоставляет доступ как к таблицам, а TQuery позволяет выполнять произвольные запросы. Если с TQuery все понятно – он выполняет тот запрос, который написан в свойстве TQuery.SQL – то TTable скрывает очень много подробностей своей работы от программиста. Без SQL Monitor увидеть все тонкости невозможно (если кто не знает – SQL Monitor находится в меню Database).Итак, запустите Delphi, откройте SQL Monitor, положите на форму компонент TDatabase, подсоединитесь к серверу, затем положите компонент TTable, присоедините его к алиасу TDatabase и выберите любую таблицу из списка (свойство TableName). Переключитесь на SQL Monitor, сотрите все что там появилось, переключитесь обратно, и включите TTable.Active:=True;
Смотрим в SQL Monitor (лог с самого начала):
- первым запросом BDE хочет убедиться, что выбранная нами таблица существует.
- второй запрос выбирает список полей выбранной таблицы, их названий, типов, условий проверки и т. п.
- третий запрос выбирает информацию об индексах указанной таблицы. Определяется, есть ли среди них первичный ключ, и по каким полям построены индексы.
- четвертый запрос почти повторяет второй, и выбирает информацию о полях – условия проверки, "вычисляемость" поля, допустимость NULL и прочее.
- собственно, пятый запрос открывает таблицу, формируя запрос SELECT FIELD1, FIELD2, ... FROM TABLE ORDER BY PK_FIELD ASC.
Заметьте, что подобные запросы выполняются каждый раз при открытии таблицы (любой) компонентом TTable. Перечитывания этих данных можно избежать, если включить у используемого алиаса параметр ENABLE SCHEMA CACHE. При этом считанную первый раз информацию BDE размещает на диске в указанном каталоге (SCHEMA CACHE DIR) в специальном файле, кэширует информацию для SCHEMA CACHE SIZE количества таблиц, и держит эту информацию в кэше в течение SCHEMA CACHE TIME секунд (если -1, то вечно). Если структуры таблиц закэшированы, то при их изменении на сервере (например, добавили новое поле) приложение будет работать со старой структурой, что может вызвать серьезные проблемы в работе приложения. SCHEMA CACHE нужно использовать только тогда, когда структура базы данных определена окончательно и не изменяется. Если все же очень сильно хочется использовать кэширование структур таблиц, то не забывайте правильно установить параметр SCHEMA CACHE TIME. Или при первом за день подключении приложения к серверу сначала кэширование структур можно выключить, отсоединиться, включить и подсоединиться снова – таким образом в самом начале работы кэш структур таблиц будет создан, и будет использоваться в течение дня.
Примечание. Параметры SCHEMA CACHE не имеют абсолютно никакого отношения к механизму Cached Updates или к кэшированию данных.
Вернемся к запросу, которым TTable открыл таблицу. В конце запроса стоит указание порядка сортирвки – ORDER BY FIELD ASC. По умолчанию TTable сортирует данные в порядке поля первичного ключа. И кстати, если пользоваться свойством TTable.IndexName, то все равно к запросу будет добавляться ORDER BY INDEXFIELD ASC. Таким образом получается, что свойство IndexName при работе с SQL-серверами бессмыслено. Вместо него нужно просто использовать свойство IndexFieldNames. Даже если в этом свойстве указать поле, по которому нет индекса, то все равно BDE "прицепит" к запросу ORDER BY FIELD ASC. Кстати, BDE абсолютно игнорирует направление индекса, и всегда в запросе добавляет ASC, даже если индекс по этому полю создан как DESCENDING (по убыванию). Получается, что отсортировать таблицу в TTable по убыванию нельзя.Примечание. Можно было бы отнести этот недостаток на SQL Link для IB, но вполне возможно что просто TTable не в состоянии кэшировать и обновлять данные, отсортированные по убыванию (см. дальше о кэше данных).
Кэширование данных
Как видно из предыдущего раздела, TTable работает с таблицами сервера не каким-то хитрым образом, а формируя самые нормальные SQL-запросы. И тут начинается самое интересное. Оказывается, при выполнении запроса сервер выдает записи клиенту (приложению) по очереди и по одной записи. Причем только "сверху вниз". Как только записи на сервере кончились, сервер сообщает клиенту об этом сигналом EOF вместо выдачи очередной записи. Конечно, в некоторых современных серверах есть произвольное позиционирование и проход по выборке не только сверху вниз но и в обратном порядке, но это требует от сервера достаточно больших ресурсов.Примечание. Разумеется, клиентская часть SQL-сервера может принимать записи от сервера "пачками". Но в любом случае получение записи инициируется только вызовом функции fetch, и по этой команде "выбирается" только одна запись. Т.е. приложение получает записи по одной независимо от того, буферизируются они на сервере/клиенте или нет.
Поскольку BDE – вещь универсальная, то он должен обеспечить возможность перемещения по записям вверх и вниз независимо от сервера. Т. е. он должен обеспечивать кэширование записей самостоятельно. Взял запись с сервера – положил в кэш. Это означает, что если вы открыли таблицу в 100 тысяч записей, и нажали в гриде Ctrl-End, то все 100 тысяч записей "приедут" к вам на клиентский компьютер. С таким пожиранием ресурсов надо как то бороться. Если в TQuery можно ограничить количество выбираемых записей условиями запроса, то в TTable этого сделать нельзя, поскольку как мы уже видели, TTable формирует запросы самостоятельно.
Живой и мертвый кэш, или TTable и TQuery
Для решения проблем кэширования TTable было введено два разных механизма кэширования. Для TTable – "живой" кэш, а для TQuery – "мертвый". Для простоты лучше сначала рассмотреть "мертвый" кэш. Вообще тут и рассматривать нечего – при перемещении по записям записи помещаются в кэш. Как только все записи помещены (пользователь "доехал" до конца выборки каким-либо способом), обращения к серверу прекращаются, и любые передвижения пользователя по записям совершаются только в кэше.У "мертвого" кэша есть побочный эффект – если вызвать метод Locate для поиска записи, то TQuery принудительно выберет все записи в кэш, и только потом будет искать нужную запись в кэше. Собственно, пока запись не считана, неизвестно – попадает она под условие Locate или нет. Поэтому другим способом здесь искать записи невозможно.
"Мертвый" кэш существует до тех пор, пока запрос не будет закрыт (TQuery.Close).
Живой кэш более сложен, и для его понимания придется использовать чуть больше компонент на уже открытой в Delphi форме. Добавьте к TDatabase и TTable компоненты TDataSource и TDBGrid. Grid растяните по вертикали так, чтобы в нем было видно штук 5 записей (7, или 9, не больше). Желательно чтобы в таблице при этом было не меньше 20-30 записей. Поместите кнопку рядом с Grid-ом, в которой на OnClick напишите
Table1.IndexFieldNames:='FIELD';
где FIELD – любое имя поля открытой таблицы, главное чтобы не поле первичного ключа. Наличие индекса по этому полю не обязательно.Скомпилируйте приложение, запустите его (не забыв запустить SQL Monitor). Поместите курсор грида посередине, как показано на рисунке (на содержимое грида не обращайте внимания – у вас оно будет совершенно другим, в зависимости от выбранной таблицы).
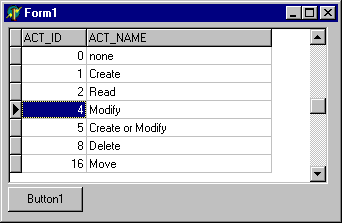
Сотрите все в SQL Monitor. И нажмите кнопку Button1. Теперь возвращаемся к началу лога в SQL Monitor:
- первый запрос выбирает значение поля, по которому нужно отсортировать данные.
- второй запрос выбирает данные от текущей записи и "выше" – см. добавку WHERE FIELD < ? ORDER BY FIELD DESC
- третий запрос выбирает запись, которую нужно поместить на место текущей (выборка запомненного первым запросом значения). Кстати, этот запрос у меня почему-то выполнился аж три раза (BDE 5.1.1). Раньше он обычно выполнялся всего один раз.
- четвертый запрос выбирает данные от текущей записи и ниже – см. добавку WHERE FIELD > ? ORDER BY FIELD ASC
Вот это и есть "живой" кэш. Т. е. при любых операциях перемещения по набору данных, отличных от перемещения на одну запись (или PageUp/PageDown) вверх или вниз, TTable уничтожает текущий кэш, перечитывает данные столь экзотическим образом, и создает новую копию кэша. По количеству вызовов isc_dsql_fetch вы можете понять, что как "вверх" так и "вниз" от текущей записи второй и четвертый запросы выбрали ровно столько записей, сколько помещается в Grid. Если вы продолжите движение курсором по одной строке вверх или вниз, то увидите каким способом (зачастую неэффективным) BDE довыбирает необходимые записи (особенно неэффективность проявляется при движении вверх).
Если же курсор находится вверху или внизу грида, то вместо трех запросов отображения данных будет два – выборка текущей записи и выборка записей только вверх или вниз от текущей записи.
Существенный момент – выборка "вверх" всегда использует сортировку по убыванию. Если по полю сортировки нет индекса по убыванию, то Interbase (или другой сервер) будет сортировать результат в памяти или на диске, что существенно медленнее сортировки с использованием индекса. Поэтому "резкие" перемещения, например в конец таблицы при помощи Ctrl-End будут приводить к значительной паузе, пока сервер отсортирует данные и выдаст результат. Повысить скорость в этом случае можно только использованием ClientDataSet, который сортирует кэш вместо выдачи серверу SQL-запросов.
Locate в живом кэше в отличие от мертвого кэша выполняется намного быстрее, т. к. TTable применяет ту же самую технику очистки кэша для поиска нужной записи.
Фильтрация
Фильтрация TTable и TQuery происходит с учетом живого или мертвого кэша. Для TTable при наложении фильтра конструируется соответствующий SQL-запрос, а TQuery производит фильтрацию буквально при помощи Locate (т. е. сначала выбираются все записи в кэш, а затем идет фильтрация уже в кэше).О вреде UNIQUE constraint
В Interbase уникальность поля можно обеспечить тремя способами: создать первичный ключ, создать unique constraint, и создать уникальный индекс. Но при чем здесь Interbase? А при том, что BDE открывает TTable по умолчанию с использованием уникального индекса. Если таблица одновременно содержит как первичный ключ, так и unique constraint, то в результате у таблицы 2 уникальных индекса. При обращении к списку индексов TTable берет для сортировки по умолчанию первый попавшийся. Если уникальность поля обеспечивается обычным уникальным индексом, то проблем нет. А вот если та же уникальность обеспечивается через UNIQUE constraint, то при backup/restore базы данных есть шанс что порядковые номера индексов поменяются (поскольку для IB это constraint целостности), и BDE будет брать в качестве первого попавшегося индекс от unique constraint вместо индекса от primary key. Вреда от этого, в общем, никакого нет, но в результате это вызывает нежелательный порядок сортировки по умолчанию в приложениях."Живые" запросы
Если способность TTable редактировать и удалять записи ни у кого не вызывает удивления, то TQuery требует, чтобы свойство RequestLive было установлено в True. Если при False запрос отправлялся непосредственно на сервер, то при True запрос предварительно обрабатывается локальным SQL (модуль IDSQL32.DLL). Это необходимо для того, чтобы TQuery смог сформировать запросы INSERT/UPDATE/DELETE на основании заданного SELECT. Для TTable построение таких запросов не представляет сложности, т. к. задано только имя таблицы, имена полей считаны и т. п. А существующий SQL-запрос нужно синтаксически разобрать, чтобы понять, сколько в нем используется таблиц, какие выбираются поля и из каких таблиц, и можно ли вообще сформировать запросы на вставку, обновление и удаление данных.Именно таким разбором SQL и занимается Local SQL. Разумеется, он поддерживает весьма ограниченный синтаксис SQL, что не позволяет делать "живыми" запросы, использующие расширенные конструкции SQL, пользовательские функции или специфические для конкретного сервера особенности. Например, для организации живого запроса вместо
SELECT * FROM TABLE
WHERE FIELD STARTING WITH 'A'
придется писать
WHERE FIELD STARTING WITH 'A'
SELECT * FROM TABLE
WHERE FIELD LIKE 'A%'
WHERE FIELD LIKE 'A%'
Подобную замену еще можно пережить, но не всегда возможно найти замену конструкции, которую не понимает Local SQL, и прекрасно понимает сервер.
Примечание. Вы сами можете убедиться в изложенном, поместив первый запрос в TQuery, переключив RequestLive в True. Попытайтесь установить Active компонента в True и посмотрите что получится.
Собственно, как вы поняли, на самом деле никаких "живых" запросов не существует. В SQL оператор SELECT выполняет только чтение, а вставить, обновить или удалить записи можно только операторами INSERT, UPDATE и DELETE, и никак иначе.При переключении TQuery.RequestLive:=True TQuery начинает вести себя как TTable – т. е. он сначала разбирает запрос, извлекает оттуда имя таблицы, и потом выбирает информацию из системных таблиц о полях таблицы, индексах и т. п. Вы можете все это увидеть в SQL Monitor.
Кроме RequestLive можно еще воспользоваться и компонентом UpdateSQL. Об этом см. дальше в разделе CachedUpdates.
SQLQUERYMODE
Кроме RequestLive на выполнение запросов влияет и параметр алиаса или драйвера IB SQLQUERYMODE. Когда этот параметр установлен в LOCAL, BDE всегда производит разбор SQL-конструкций при помощи Local SQL. Если параметр установлен в "пусто", то BDE сначала пытается отправить SQL на сервер, а при получении ошибки пытается выполнить его Local SQL. При установленном параметре SERVER запросы всегда отправляются только на сервер (за исключением "живых").Таким образом, при установке LOCAL запросы будут всегда выполняться локальным ядром SQL BDE, и функциональность SQL IB будет недоступна (не будут выполняться запросы с containing и др. синтаксисом, который не поддерживает Local SQL). Избавиться от такого поведения лучше всего установив раз и навсегда значение SERVER.
Refresh и атомарность запросов
Читатель уже после информации о живом и мертвом кэше, наверное, давно хочет спросить – а как же BDE видит новые записи, добавляемые другими приложениями? Да никак. С TTable все понятно – в любой момент можно вызвать refresh, что приведет к удалению "живого" кэша и переоткрытию TTable как мы уже видели в разделе о кэшах записей. TTable перед своим закрытием запоминает запись, на которой стоял курсор грида, и поэтому после открытия может спозиционироваться на эту же запись.TQuery работает с "мертвым" кэшем, поэтому обновлять его невозможно. BDE не знает о том, какое из полей в запросе является первичным ключом, да и вообще по скольким таблицам построен запрос. Поэтому единственным вариантом для refresh является переоткрытие TQuery (Close/Open). Текущая запись при этом будет потеряна. Можно, правда, попытаться использовать TBookmark чтобы запомнить запись и вернуться к ней после открытия TQuery, но как и Locate это вызовет выборку всех записей с сервера в кэш TQuery и при большом количестве выбираемых записей может занять длительное время.
Примечание. Даже если компонент IBX IBTable и поддерживает Refresh, то он его выполняют точно таким же образом, что и BDE. А компонент IBDataSet выполняет Refresh только для одной, текущей, записи.
В чтение актуальных данных вмешивается еще и атомарность операторов SQL. Применительно к SELECT это означает, что он будет выбирать только те записи, которые существовали на момент выполнения этого SELECT. Это означает, что если открыть TQuery, а затем через 5 минут подсоединить его к гриду, то в нем будут видны только те записи, которые были в базе данных 5 минут назад. Даже если за это время это же самое приложение в этой же транзакции успело добавить, изменить или удалить 1 или сколь угодно большее количество записей, попадающих под условия выборки данного SELECT.В буквальном смысле это означает, что если вставить запись в открытый select, то увидеть новую запись нельзя. Для этого придется переоткрыть запрос. По отношению к TQuery это справедливо, а вот TTable "обманывает" пользователя, помещая данные успешно вставленной записи прямо в свой собственный кэш. Таким образом, вставка в TTable как бы помещает данные прямо в открытую выборку. Чего, собственно, на самом деле на сервере не происходит.
Вообще перечитывание данных почти всегда вызывает проблемы. Сервер не уведомляет клиентов, что определенные записи изменились, появились или были удалены. EventAlerter может сообщить только информацию что некое событие (например, была изменена таблица) произошло, но не "номер записи". В многопользовательской среде перечитывание данных по таймеру может вызвать большой сетевой трафик. Да и кроме того, клиент обычно видит в гриде только какую-то часть данных, и идеальным вариантом было бы не только узнать, что в именно этой части данных произошли изменения, но и перечитать только эту часть. В итоге, самым разумным вариантом является помещение в приложение на нужную форму кнопки Refresh (Перечитать). Пусть пользователь решает, когда ему нужно это сделать.
Примечание. В отличие от атомарного SELECT, оператор FOR SELECT внутри процедур IB не является атомарным. Т. е. если в цикле FOR SELECT добавлять записи, то они могут попасть в область видимости FOR SELECT, и может произойти "бесконечный цикл". Также в IB неатомарной является конструкция INSERT INTO ... SELECT FROM.
Завершение транзакций
BDE устроен так, что компонент TDatabase может работать только с одной транзакцией одновременно. При этом может быть два режима – неявная работа с транзакциями (AUTOCOMMIT, NOAUTOCOMMIT), и явная работа с транзакциями (методы StartTransaction, Commit и Rollback). В режиме AUTOCOMMIT BDE самостоятельно завершает транзакцию и стартует новую при любых модификациях данных (insert/update/delete) или при вызове TStoredProc.ExecProc. Таким образом изменения автоматически сохраняются в базе данных. Однако чтение данных и вообще работа с ними может быть выполнена только в контексте транзакции. Т. е. вне транзакции с данными работать нельзя, т. к. не будет обеспечиваться целостность данных. При этом данные, прочитанные в одной транзакции, неактуальны для другой транзакции. Если посмотреть справку BDE32.HLP по функции dbiEndTran, то можно обнаружить, что BDE при завершении явной или неявной транзакции ведет себя следующим образом:- открытый query довыбирает данные
- открытый table закрывается
Другие случаи я не упомянул, потому что IB SQL Link их не поддерживает. То есть при любом завершении транзакции (и открытии новой) данные будут перечитываться. Для TTable это не смертельно, т. к. он знает первичный ключ записи, на которой стоял курсор грида, и может перечитать немного данных, чтобы заново отобразить их. А вот для TQuery, который не знает никаких первичных ключей, происходит полная выборка всех данных, что эквивалентно вызову Locate, FetchAll или Last. Так что если ваше приложение при обновлении данных почему-то сильно тормозит, или возникают паузы, то нужно срочно смотреть в SQL Monitor, какие именно запросы перечитываются.
Примечание. Иногда по неизвестным причинам BDE перечитывает запросы, которые совершенно этого не требуют. Например, мне встречалась ситуация с неявным перевыполнением запроса при перемещении по grid-у detail-таблицы, причем запрос никак не был связан ни с master ни с detail-таблицами. Избавиться от проблемы не удалось.
Соответственно, чтобы предотвратить плохую производительность, нужно или держать минимум данных открытыми в TQuery, или стремиться к минимизации количества записей, выбираемых TQuery. Также можно открыть второй TDatabase, и работать например со справочными таблицами только в нем. Таким образом изменения будут идти в одном коннекте, и не будут вызывать завершение транзакции и перечитывание данных в другом. В компонентах прямого доступа это решается более простым способом, т. к. там поддерживается произвольное количество транзакций для одного коннекта. Есть, кстати, и оригинальное решение, которое позволяет использовать коннект TDatabase совместно с компонентами FreeIBComponents или IBX:
var h: tisc_db_handle;
DB:=TIBDatabase.Create(nil);
try
Dbtables.Check(DbiGetProp(HDBIOBJ(DMCommBilling.Database.Handle),
dbNATIVEHNDL, @h, sizeof(tisc_db_handle), l));
DB.DBName:='Cloned';
DB.Handle:=h;
TR:=TIBTransaction.Create(nil);
try
и так далее. Таким образом, в приложении BDE можно дополнительно обрабатывать данные в транзакциях IBX. Приложение получается комбинированным, поскольку для доступа к данным в новой транзакции придется использовать компоненты IBX.
DB:=TIBDatabase.Create(nil);
try
Dbtables.Check(DbiGetProp(HDBIOBJ(DMCommBilling.Database.Handle),
dbNATIVEHNDL, @h, sizeof(tisc_db_handle), l));
DB.DBName:='Cloned';
DB.Handle:=h;
TR:=TIBTransaction.Create(nil);
try
Record/Key deleted
Надо сказать, что BDE облегчает жизнь программисту хотя бы тем, что перечитывает запись, которую собирается редактировать пользователь. Т. е. как только BDE переводит TTable или "живой" TQuery в режим Edit, он производит выборку текущей записи (по первичному ключу) и показывает для редактирования самые последние, актуальные, данные. Правда, пока пользователь редактирует запись, ее могут изменить или даже удалить другие пользователи – BDE никоим образом не "блокирует" запись, которая редактируется, т. к. в SQL вообще нет команды вроде "заблокировать запись". Поэтому после Post клиент может обнаружить, что его изменения не попадут в базу данных, т. к. запись уже изменилась или удалена. И обнаружит он это или нет, зависит от режима TDataSet.UpdateMode.UpdateMode имеет 3 режима:
- upWhereAll, по умолчанию – BDE пытается сделать UPDATE с внесением в условие WHERE всех значений полей, которые были ДО момента редактирования. Если при этом произошла ошибка, значит хотя бы одно поле у редактируемой записи уже было кем-то изменено (с момента входа в режим редактирования до момента Post).
- upWhereChanged – BDE пытается сделать UPDATE с условием WHERE, проверяющим старые значения только измененных полей. Т.е. чтобы убедиться, что пользователь поменял именно те значения полей, которые видел, на новые. Если произошла ошибка, то это значит что одно из изменяемых полей было уже кем-то изменено.
- upWhereKeyOnly – BDE обновляет запись, устанавливая в WHERE поиск записи только по ее первичному ключу.
Соответственно, если запись не найдена, то выдается упомянутое в заголовке сообщение Record/Key deleted.
Примечание. Найдена запись или нет, определяется анализом переменной RowsAffected, куда заносится информация после выполнения запросов UPDATE/DELETE. Если RowsAffected = 0, то Record/Key Deleted.
С RowsAffected связана еще одна проблема, когда BDE для "живых" запросов при использовании TUpdateSQL обязательно требует чтобы после выполнения запроса RowsAffected был равен 1. Если RowsAffected > 1 то выдается exception и неявная транзакция откатывается (rollback) (идея состоит в том, что раз в гриде вы стоите на одной записи, то при изменении или удалении этой записи изменяться должна тоже одна запись). Из-за этого запросы update и delete, которые должны соотвественно изменить или удалить более одной записи, приходится выполнять в отдельном TQuery.Обратите внимание, что успешное обновление записи в режимах upWhereChanged или upWhereKeyOnly может вызвать проблемы с конкурентным обновлением. Например, существует таблица TABLE, у которой три поля: ID, NAME и PRICE. Два пользователя открывают таблицу. Один видит, что для данного имени товара неверно указана цена. Другой счел, что цена правильная, только имя товара указано с ошибкой. У обоих UpdateMode установлен в upWhereKeyOnly или upWhereChanged. После изменения пользователи по очереди нажимают Post (вероятность одновременного нажатия достаточно низка, а кто из них нажал на кнопку первым не имеет значения). В результате оказалось изменено и название товара и его цена, и комбинация этих полей опять содержит неправильную информацию!
В данном частном случае избавиться от проблемы можно установкой UpdateMode только upWhereAll, чтобы запрос при обновлении проверял все зависимые поля. Или можно подключить компонент TUpdateSQL и прописать для обновления данных запрос, который будет проверять на "старые" значения и имя товара и его цену. Однако работать с TUpdateSQL без CachedUpdates невозможно.
Другая причина, по которой может происходить сообщение Record/Key deleted – перечитывание данных после их обновления. BDE таким образом (по крайней мере для TTable) пытается вставить запись в нужное место (в порядке сортировки) кэша. Но если после вставки или обновления запись на сервере изменилась – другим пользователем, default-условием или триггером (с генератором) – то BDE не сможет ее найти и выдаст упомянутое сообщение.
Если запись от момента редактирования до момента перечитывания была изменена другим пользователем, то тут ничего нельзя сделать. Если это был default или триггер, то вполне возможно, что лучше отказаться от считывания таких полей в DBGrid (вызовите FieldEditor). Если же это поле первичного ключа, которому в триггере присваивается значение генератора, то вам явно стоит прочитать старую статью, которая за 5 лет не потеряла своей актуальности.
RecordCount
Получение количества записей – самая вредная функция (или свойство). Вред ее в том, что клиент SQL-сервера (и сам сервер) до выборки последней записи не знает, сколько там их еще будет. Поэтому RecordCount в BDE обрабатывается двумя способами:- TTable – поскольку известно имя таблицы, автоматически формируется запрос select count(*) from tablename. В Interbase это может привести к сборке мусора, и даже без нее будет выполняться достаточно долго, т. к. в силу многоверсионности IB для определения количества записей просматривает все версии записей таблицы, и определяет, какие из них "видны" данной транзакции.
- TQuery – если запрос "редактируемый", то BDE может сформировать select count(*) как в случае TTable. Но это удается не всегда, и обычным способом подсчета количества записей является внутренний FetchAll и подсчет закэшированных записей. Понятно, что при большом количестве записей, которые возвращает запрос, это тоже будет долго и основная нагрузка ляжет на сеть и клиента.
Другие клиентские библиотеки, как IBObjects, FreeIBComponents или IBX могут совершенно по другому "обслуживать" вызов RecordCount. Например FIBC и IBX в качестве возвращаемого значения используют текущее количество считанных записей в буфере. Т. е. после IBQuery.Open значение будет равно 0, затем по мере вызовов Next будет увеличиваться, и остановится только после EOF (или FetchAll), когда будут выбраны все записи. Такое поведение необходимо учитывать, чтобы при переходе с BDE на другие наборы компонент не пришлось сильно менять код приложения.
Примечание. Если говорить о count, т. е. подсчете количества записей в Interbase/Firebird, то в многопользовательской среде разные пользователи могут видеть разное количество записей в одной и той же таблице из-за версионности. Таким образом, результат count можно рассматривать только как приблизительный.
Cached Updates
При работе без CachedUpdates изменения, производимые над данными, отправляются на сервер немедленно. Это достаточно удобно, т. к. позволяет немедленно обнаруживать конфликты изменений, но не всегда хорошо для сетевого трафика если нет явного управления транзакциями или приводит к накоплению версий записей при длительных явных транзакциях. В первую очередь режим CachedUpdates подходит для "блокировочных" серверов, в которых чтение данных блокирует их от изменения (например, MS SQL, Sybase).CachedUpdates позволяет накопить изменения, и затем "выстрелить" их на сервер одним пакетом. При этом время блокировок минимально, минимален также сетевой трафик, но существует высокая вероятность что данные уже успели измениться. Поэтому при использовании CU необходимо тщательно планировать именно процесс обращения к таблицам и режимы UpdateMode.
За более подробной информацией по CachedUpdates обращайтесь к документации или к книге Шумакова ("Delphi 3 и создание приложений баз данных", в том числе последующие издания для Delphi 4 и 5 в соавторстве с Фароновым), где все это очень хорошо описано. Нас сейчас CU больше интересует как замена RequestLive.
Действительно, "оживление" запроса выполняется следующим образом – к компоненту TQuery подключается компонент TUpdateSQL, в котором прописываются вручную или автоматически запросы на вставку, удаление или изменение записи. Заметьте, только одной записи. После включения CachedUpdates:=True при модификации данных именно эти запросы, а не конструируемые Local SQL при RequestLive=True, будут отправляться на сервер (отправляются они только в момент ApplyUpdates, а не в момент реального обновления записи).
Самым непонятным является то, почему связка TQuery и TUpdateSQL не может работать без CachedUpdates. Например компоненты IBX без проблем обеспечивают такой режим, да и вообще там у TIBQuery нет свойства RequestLive (т. к. нет парсера SQL на клиентской стороне). Т. е. в IBX, конечно, можно использовать CachedUpdates, но разве что при действительной в нем необходимости.
Гетерогенные запросы
BDE обладает уникальной способностью выполнять запросы, которые обращаются к таблицам, находящимся на разных серверах баз данных (или к таблицам разных форматов). Это так называемые "гетерогенные" запросы. Иногда их называют "распределенными", т. к. данные "распределены" по разным базам данных возможно одного и того же SQL-сервера.Выполнить гетерогенный запрос можно следующим образом:
- открыть 2 или более TDatabase, каждый для соответствующей базы данных. Например, один компонент подсоединен как A к алиасу TEST, а другой, как B к алиасу TEST2.
- открыть третий (!) TDatabase, который подсоединен к драйверу типа STANDARD(т.е. к локальным таблицам. Существование оных необязательно). См. окно свойств TDatabase.
- выполнить запрос в компоненте TQuery, подсоединенном к "стандартному" TDatabase. В результате должна получиться такая "конструкция"
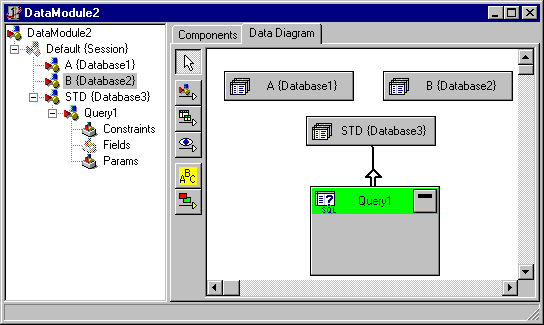
а запрос иметь вид
SELECT C.CLIENT_NAME
FROM ":A:CLIENTS" C, ":B:EMPLOYEE" E
WHERE E.EMP_NO = C.CLIENT_ID
FROM ":A:CLIENTS" C, ":B:EMPLOYEE" E
WHERE E.EMP_NO = C.CLIENT_ID
Конечно, по смыслу этот запрос – полная чушь, но зато пример показывает указание таблиц из разных базах данных. Еще один пример запроса можно найти по ключевой фразе 'heterogeneous joins' в BDE32.HLP.
Пока я готовил и проверял этот пример, установка Query1.Active в true вызывала страшные содрогания винчестера. Дело в том, что подобные запросы выполняются следующим образом:
- ядро Local SQL "разбирает" запрос, и выясняет, какие таблицы из каких баз данных используются в запросе
- данные из каждой таблицы вытаскиваются в локальный кэш (т. е. на клиента), в память или временные таблицы.
- извлеченные данные обрабатываются локальным SQL (join, where, order by и т. п.).
Однако происходит так не всегда. По крайней мере в моем тестовом случае Local SQL начал выполнять просто чудовищные операции:
Сначала для одной, а затем для другой таблицы был выполнен SELECT COUNT(*). Т. е. Local SQL сначала пытается понять, во что ему обойдется скачивание данных на клиентскую часть. Очевидно, записей в CLIENTS ему показалось мало, и он вытащил все записи из EMPLOYEE, а потом начал последовательно выбирать соответствующие записи из CLIENTS отдельными запросами для каждой записи (проверяя соответствие условия WHERE). Буквально SELECT ... FROM CLIENTS WHERE CLIENT_ID = ? ORDER BY CLIENT_ID ASC. (Зачем здесь нужен order by – неизвестно). Почему произошло не наоборот, т. е. меньшая таблица не была выбрана в память, неясно.
Можно даже не упоминать, что select count(*) на реальных данных может выполняться долго (даже без учета возможной сборки мусора). Не говоря о том, что в EMPLOYEE было 42 записи, и отдельных запросов к таблице CLIENTS получилось тоже 42.
Вот такая веселая арифметика. Зато получены четкие объяснения, почему "трещал" винчестер.
Однако, пусть даже и таким жутким способом, но BDE умеет выполнять гетерогенные запросы. Благодаря Local SQL и тому, что BDE умеет работать с локальными таблицами (которые он использует для хранения промежуточных данных таких запросов). Ни IBObjects, ни fibc/IBX, ни IB API не имеют таких возможностей, и соответственно, не могут выполнять гетерогенные запросы.
Итог
После прочтения этой статьи может сложиться впечатление, что BDE вообще не пригоден для работы с SQL-серверами. На самом деле это не так. Если знать его архитектуру (надеюсь, статья вам в этом помогла), то можно снизить неэффективность BDE в приложениях до минимума.Другой важный момент – скорость разработки. Она до сих пор остается самой высокой по сравнению с другими наборами компонент (даже с IBObjects). А скорость разработки – это в первую очередь более низкая стоимость разработки системы.
Кстати, может оказаться, что вся эта "неэффективность" в смысле большого объема передаваемых данных на вашей 100мбит сети и не проявится. А если сеть гигабитная, то вы вообще никакого лишнего трафика не заметите. И наоборот – для модемных соединений BDE, конечно, никуда не годится. Или если вам нужно тщательное планирование и управление транзакциями IB, то BDE здесь тоже делать нечего.
Есть и более жесткие критерии выбора – если вы собираетесь переходить на Kylix или IB6 (диалект 3), то c BDE придется расстаться. Если же в течение ближайшего года или полутора вы не собираетесь этого делать – забудьте об альтернативах и продолжайте работать привычным способом.