 En
EnБаза размером 1 терабайт на Firebird. Технический отчет
iBase.ru, IBSurgeon, 22.06.2009.
Идея попробовать создать в Firebird базу размером 1 терабайт возникла после ознакомления с достижениями в этой области – на текущий момент наибольшая база данных (с осмысленной информацией) под Firebird – 450 гигабайт (указано в упрощенном варианте отчета).
Мы не стали собирать мощный сервер в тестовой лаборатории, привлекать спонсоров, и т. п. Мы просто пошли в ближайший магазин, и купили там SATA-диск на 1.5 терабайт (за 4500 руб – $142), и подключили его к десктопному компьютеру. Конфигурация получилась следующая:
- AMD Athlon 64 x2 5200. Работает на частоте 2782МГц вместо 2600МГц
- 4GB RAM
- Windows XP Professional SP3, 32bit
- MB MSI K9N Platinum
- NVIDIA GeForce 8800GT
- ОС и temp – ST3160815AS, 160GB, SATA II
- Вспомогательный – ST3200827AS, 200GB, SATA II
- Свежекупленный – ST31500341AS, 1.5TB, SATA II (Firmware CC1H)
Место для размещения будущей терабайтной базы есть, теперь надо решить, чем ее заполнить – для этого был выбран тест TPC-C, вернее, не сам тест, а загрузчик для теста. Таким образом, у нас будет OLTP-база в 1 терабайт.
Почему именно на десктопном компьютере, а не на сервере? Во-первых, так проще выполнить тест. Во-вторых, задача теста состоит в том, чтобы проверить возможность работы Firebird с такими большими базами, как таковыми. В третьих, сам факт о возможности работы с терабайтной базой данных на таком компьютере уже говорит о масштабируемости Firebird.
Результаты, полученные в тесте, вы можете примерить на ваше оборудование, которое может быть в 2, 3, 10, 20 раз мощнее (или окажется в 1.5, 2 или 3 раза хуже). Например, если вместо одного SATA-диска соорудить RAID 10 из 4-х таких же дисков, то весь тест скорее всего прошел бы раза в полтора быстрее.
Для теста был выбран Firebird 2.1.2.
Примечание KDV. В 1998 году, работая в Epsylon Technologies, мне удалось протестировать InterBase 5.1 в тестовой лаборатории Intel. Тогда я примерно трое суток без перерыва заливал данные, на страшно мощном 4-процессорном сервере, с очень быстрыми дисками. За 3 дня залилось примерно 26 гигабайт. Центральная таблица содержала примерно 5 миллионов записей (не помню точно), и создание индекса по целочисленному столбцу занимало примерно 1 час.
План теста
- Создать базу данных, без индексов, размером в 1 терабайт
- Создать индексы (штатные для TPC-C)
- Собрать статистику по БД
- Проверить работу запросов
Заливка данных
Само тестирование, как и предполагалось, оказалось не для слабонервных – прямо сразу при форматировании диска возникли проблемы:- после подключения диска XP SP3 при загрузке упала в синий экран,
- диск инициализировать без проблем удалось на этой же машине в параллельно установленной Vista Business 64bit,
- в Vista попытка быстрого форматирования выдавала ошибку,
- в XP быстрое форматирование ошибку не выдавало, но и не форматировало.
В результате запустили полное форматирование под XP, которое длилось 6.5 часов (!). После этого провели пробные тесты загрузчика TPC-C на возможность заливать данные порциями. Весь шик этого теста состоял в том, что терабайтная база должна быть не просто на десктопном компьютере, но еще и на котором работают (по крайней мере днем). Так что "порционность" заливки была однозначной необходимостью – вдруг понадобится перезагрузить компьютер, или еще что. Кроме этого, благодаря "порционности" появилась возможность производить измерения в промежутках между ростом базы данных.
Для заливки данных использовался Firebird SuperServer, т. к. загрузчик в основном производит только вставку, а в этом смысле производительность у SuperServer и Classic одинаковая. Первые 43 гигабайта были залиты за 2.5 часа, порциями по 100 warehouses (-W), после чего была собрана статистика (файл iba для IBAnalyst 2.x). Статистика собиралась 15 минут.
Далее заливка данных осуществлялась большими порциями.
При размере базы в 250 гигабайт была сделана остановка, и опять собрана статистика. Время сбора статистики – 1 час 48 минут (статистика в txt). Из этого было сделано предположение, что по финальной базе статистика будет собираться примерно 8 часов.
Далее заливка была продолжена. Во дневное время одновременно происходила работа в: Word, Excel, бухгалтерском ПО, PerfMon, TaskManager, DreamWeaver, FireFox, Chrome, TheBat… То есть, самая обычная офисная работа.
Скорость загрузки одного блока (100 warehouses) с течением времени приведена на графике. По вертикали – скорость заливки одного блока (чч:мм:сс), а по горизонтали – номер блока. Вы видите 3 плоских участка – это заливка ночью.
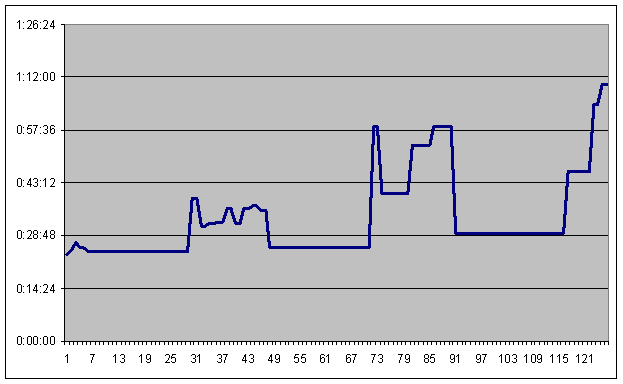
Всего чистого времени заливка заняла 70 часов (почти трое полных суток). С небольшими перерывами – 4 суток. Fbserver.exe в это время занимал примерно 80% процессорного времени одного ядра (или 40% двух), а загрузчик – от 5 до 40% одного ядра (посередине теста загрузчик было решено привязывать ко второму ядру, чтобы он не мешал fbserver.exe и не терял производительность на переключении между ядрами).
В сумме в базу было залито 6.2 миллиарда записей размером от 13 до 600 (в среднем 146) байт. Средняя скорость вставки записей – 24.5 тысячи в секунду (общее число записей поделить на время заливки).
Разумеется, по ночам скорость заливки не была постоянной. Мы с некоторым опозданием (примерно на 420 гигабайтах) догадались включить FBDataGuard – вот картинка роста размера базы данных и интенсивности транзакций (желтым цветом – транзакций в минуту):
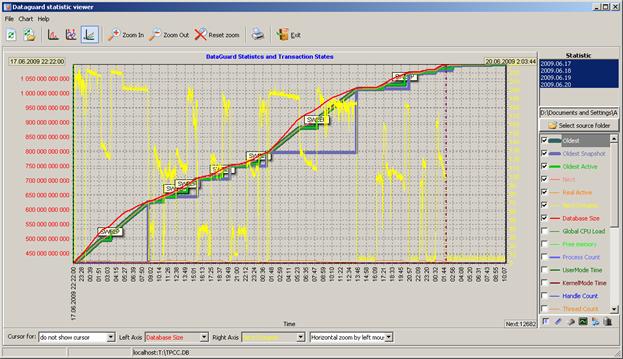
Замедление вставки данных, похоже, не связано с размером БД, а скорее связано с особенностями загрузчика. Например, видно еще на 460 гигабайтах падение частоты старта транзакций с 200 до 100, а потом опять возрастание до 200. Днем запускались мелкие блоки, у них падение было вообще до 40 транзакций в минуту, а на 770 гигабайт, ночью, опять рост до 200.
Мы специально сохранили всю статистику от FBDataGuard, так что ее можно посмотреть, тем более в ней же сохранена статистика по состоянию системы (свободная память, кол-во тредов fbserver.exe, и т. п.), однако графиков много, и лучше их наблюдать в DataGuard Statustics Viewer от FBDataGuard Community Edition. Например, на этой картинке за 19.06.2009 мы попытались свести вместе
- частоту старта транзакций
- количество свободной памяти
- количество хэндлов и тредов fbserver.exe
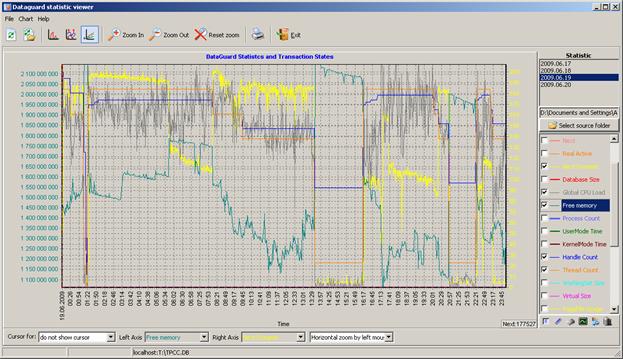
В частности, по Free Memory видно, что оно не опускалось ниже 1гб, и практически не связано с интенсивностью старта транзакций.
Тем не менее – ура! У нас теперь есть база данных размером 1 терабайт (именно 1 терабайт, то есть 1 099 900 125 184 байт).
Создание индексов и select count
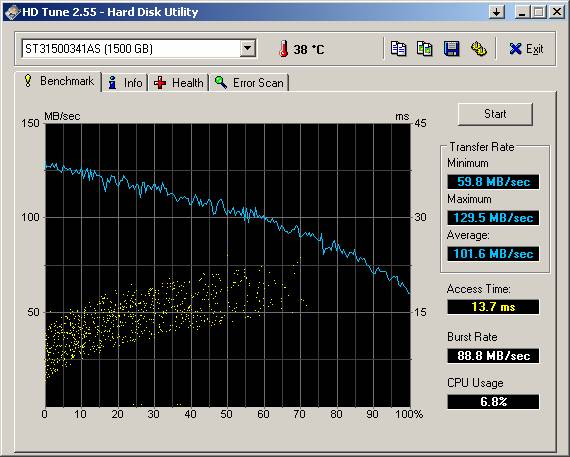
Понятно, что при таком размере базы сразу скопом все индексы лучше не создавать, т.к. это может занять очень длительное время, да и неизвестно, сколько они займут места. А свободного места на 1.5 терабайтном диске осталось 372 гигабайта.Поэтому индексы создаем поштучно. Но в любом случае при их создании создаются temp-файлы (для сортировки значений индексируемого столбца), а значит, понадобится место для TEMP. На текущем компьютере со свободным местом предполагаемого объема было не очень, поэтому решено докупить SATA диск 640 гигабайт (куплен HDT721064SLA360), заменить имеющийся 200гб с копированием данных и перераспределением разделов в Acronis True Image.
В результате на диске H образовалось свободное место 378 гигабайт, и туда через firebird.conf был назначен temp. Тест диска для TEMP в HD Tune:
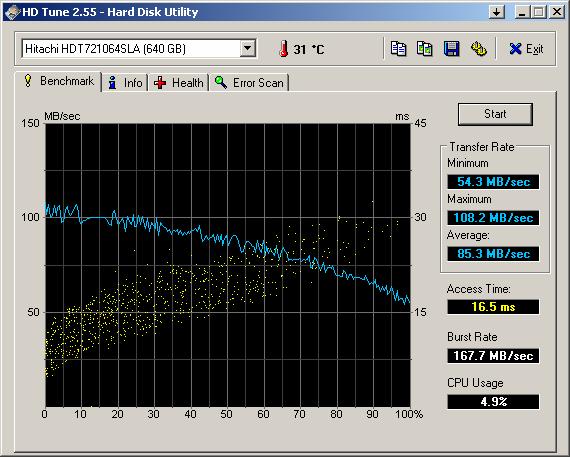
Поначалу мы решили, что собирать статистику без индексов неинтересно. Поэтому оценивали объемы таблиц, с которых можно начать индексирование, по предыдущей статистике 250 гигабайт. Также перед созданием некоторых индексов выполнялся select count, для оценки предполагаемого времени (не меньше) создания индекса по этой таблице.
Внимание! Надо сказать, что предварительные оценки скорости создания индексов были весьма пессимистичные, поскольку все таблицы (кроме ITEM) в базе "размазаны" по всему терабайту – лоадер заливает данные порциями в master-detail таблицы, почти как в реальной жизни.
Прочерки в ячейках означают, что информация или не замерялась, или неизвестна, или отсутствует.
| Таблица | Записей | Размер, Гб | Время select count(*) | Время создания индекса | Размер temp-файла, Гб | Размер индекса в БД, Гб |
|---|---|---|---|---|---|---|
| WAREHOUSE | 12400 | 0.002 | 0s | 0 | 0 | 0.0 |
| ITEM | 100000 | 0.012 | 0.7s | – | – | 0.0 |
| DISTRICT | 124000 | 0.017 | 0.7s | 6s | – | 0.0 |
| NEW_ORDER | 111 600 000 | 32 | 20m 00s | 23m 00s | 4.56 | 0.8 |
| CUSTOMER | 372 000 000 | 224 | – | 41m 00s | – | 2.6 |
| customer_last | 1h 52m 32s | 12.4 | 2.3 | |||
| fk_cust_ware | 2h 10m 51s | – | 2.3 | |||
| HISTORY | 372 000 000 | 32 | – | – | – | – |
| ORDERS | 372 000 000 | 25 | 32m 00s | 45m 41s | 15.2 | 2.5 |
| STOCK | 1 240 000 000 | 404 | – | 3h 34m 44s | 41.5 | 9.2 |
| ORDER_LINE | 3 720 051 796 | 359 | – | 12h 6m 18s | 182.0 | 29.3 |
По таблице ORDER_LINE в первый раз создать первичный ключ не удалось – не хватило 378 гигабайт в TEMP? Мало того что эта таблица содержит 3.7 миллиарда записей, так еще и первичный ключ у нее состоит из smallint, smallint, integer и smallint. Решили отложить создание этого индекса на некоторое время.
Пришло время запустить gstat (есть несколько часов не за компьютером). Итоговое время – 7 часов 32 минуты 45 секунд (финальный файл txt). В пересчете в мегабайт в секунду получается "сканирование БД" со скоростью в среднем 39 мегабайт в секунду, что очень даже неплохо (при усредненном максимальном Transfer rate для данного диска 100мб в секунду).
Однако, статистику по ORDER_LINE gstat выдал с переполнением – 574915500 записей. Мы тут же связались с Владиславом Хорсуном, и выяснили, что gstat считает количество записей в 8-байтном целом числе, а вот выводит в 4-байтовом знаковом. Значит, число записей будет 3 720 051 796 (если у отрицательного числа убрать знак).
Создан репорт http://tracker.firebirdsql.org/browse/CORE-2519 и исправлен IBAnalyst 2.6 – если он получает число записей из статистики как отрицательное, то меняет знак у числа и выводит его. Вообще в IBAnalyst 2.6 были не только эти правки, но и ряд других, касающихся переполнений при различных операциях с такими большими числами, а также обработке статистики таблиц без индексов.
Попытались создать индекс по ORDER_LINE второй раз. Опять ошибка. Сообразили, что проблема не в нехватке дисковой или физической памяти, а где-то внутри Firebird, т. к. выдаваемое сообщение
–Statement failed, SQLCODE = -904
sort error: not enough memory
sort error: not enough memory
Обратились опять к Владиславу, и он пришел к выводу, что не хватает количества блоков для сортировки, а это задается константой в коде. Создали http://tracker.firebirdsql.org/browse/CORE-2525. Владислав сделал тестовый билд Firebird 2.1.3, в котором эта константа увеличена. И создание индекса успешно завершилось за 12 часов. При этом размер файла сортировки был 182 гигабайта, а в базе индекс занял 29.3 гигабайт.
Чтобы проверить, как изменение Firebird повлияло на создание индексов, было решено повторить эксперимент с индексом на таблице NEW_ORDER, т. к. его создание занимает меньше всего времени, и первоначально составило 23 минуты.
- Firebird 2.1.2 с модификацией – 31 минута 35 секунд, 32 минуты 31 секунда
- Firebird 2.1.2 оригинальный – 23 минуты 00 секунд, 25 минут 46 секунд
Пересобрали статистику только по индексам, это заняло 14 минут, т. к. индексы находятся "плотно" в конце файла базы данных. После чего собранная статистика по индексам была "вклеена" в полученный ранее файл статистики.
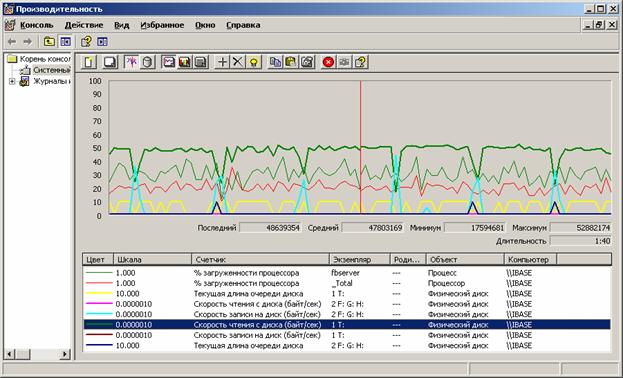
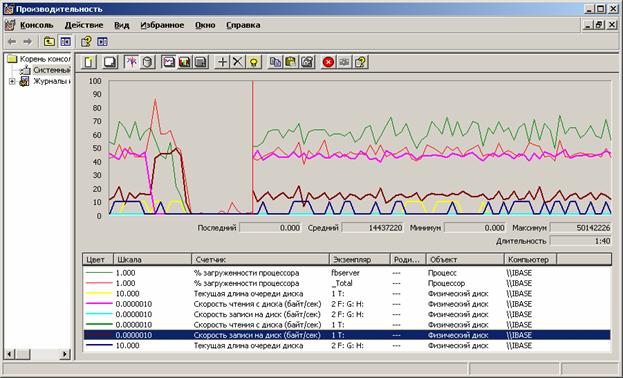
Как уже говорилось выше, создание индекса состоит из двух фаз – вначале данные из БД переносятся блоками во временный файл с одновременной сортировкой, а затем уже отсортированные данные переносятся обратно в базу данных как индекс. Мы наблюдали за этими процессами в PerfMon, вот наиболее типичные графики (для индекса customer_pk, таблица с 372млн записей).
Перенос данных в TEMP:
Перенос данных из TEMP в индекс:
Запросы
Поскольку в базе мало индексов, по выполняемым запросам есть сильное ограничение – невозможно взять и просто написать что-нибудь, потому что выборка может занять очень длительное время. Поэтому перед выполнением запроса его план тщательно проверяется.select w_id, w_name, c_id, c_last
from WAREHOUSE, customer
where c_w_id = w_id
После открытия БД prepare занимает около 20 секунд. Правда, повторная операция prepare происходит мгновенно. Это понятно – серверу в первый раз после соединения к БД необходимо загрузить метаданные, а они для таблиц и индексов находятся в очень отдаленных уголках файла БД.
where c_w_id = w_id
Plan
PLAN JOIN (WAREHOUSE NATURAL, CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 15ms
Execute time = 79ms
Avg fetch time = 6.08 ms
Current memory = 272 264 476
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 82
Writes from cache to disk = 0
Fetches from cache = 3 648
Ничего удивительного. Простое объединение, напомню что в warehouse 12400 записей, а в customer – 372 миллиона.PLAN JOIN (WAREHOUSE NATURAL, CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 15ms
Execute time = 79ms
Avg fetch time = 6.08 ms
Current memory = 272 264 476
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 82
Writes from cache to disk = 0
Fetches from cache = 3 648
Теперь чуть иначе, некоторое количество данных ближе к концу БД
select w_id, w_name, c_id, c_last
from WAREHOUSE, customer
where c_w_id = w_id and c_w_id = 10000
where c_w_id = w_id and c_w_id = 10000
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 16ms
Execute time = 78ms
Avg fetch time = 6.00 ms
Current memory = 272 266 148
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 88
Writes from cache to disk = 0
Fetches from cache = 3 656
------ Performance info ------
Prepare time = 16ms
Execute time = 78ms
Avg fetch time = 6.00 ms
Current memory = 272 266 148
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 88
Writes from cache to disk = 0
Fetches from cache = 3 656
select count(*)
from WAREHOUSE, customer
where c_w_id = w_id and c_w_id = 10000
результат – 30000.
where c_w_id = w_id and c_w_id = 10000
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 0ms
Execute time = 453ms
Avg fetch time = 453.00 ms
Current memory = 272 263 844
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 1 048
Writes from cache to disk = 0
Fetches from cache = 60 024
То есть, если не выполнять выборки миллионов записей, то скорость выполнения запросов вполне обычная.------ Performance info ------
Prepare time = 0ms
Execute time = 453ms
Avg fetch time = 453.00 ms
Current memory = 272 263 844
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 1 048
Writes from cache to disk = 0
Fetches from cache = 60 024
select w_id, w_name, c_id, c_last
from WAREHOUSE, customer
where c_w_id = w_id and (c_w_id > 8000) and (c_w_id < 10000)
where c_w_id = w_id and (c_w_id > 8000) and (c_w_id < 10000)
Plan
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 0ms
Execute time = 125ms
Avg fetch time = 9.62 ms
Current memory = 272 270 824
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 91
Writes from cache to disk = 0
Fetches from cache = 3 659
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 0ms
Execute time = 125ms
Avg fetch time = 9.62 ms
Current memory = 272 270 824
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 91
Writes from cache to disk = 0
Fetches from cache = 3 659
Посчитаем кол-во записей того же запроса:
select count(*)
from WAREHOUSE, customer
where c_w_id = w_id and (c_w_id > 8000) and (c_w_id < 10000)
59 970 000 записей
where c_w_id = w_id and (c_w_id > 8000) and (c_w_id < 10000)
Plan
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 0ms
Execute time = 13m 4s 718ms
Avg fetch time = 784 718.00 ms
Current memory = 272 268 532
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 2 332 583
Writes from cache to disk = 0
Fetches from cache = 119 977 902
Сразу после публикации общего отчета нас начали спрашивать, почему в тестовых запросах нет запросов с сортировкой. Дело в том, что на такой базе данных любой "выстрел мимо" чреват очень долгим выполнением запроса. А сидеть и выяснять, какой же объем данных можно вразумительно и недолго "отсортировать" также не было ни времени, ни желания. Поэтому оценить скорость сортировки можно по разделу, где были приведены данные по скорости создания индексов – ведь order by без индекса это тот же самый процесс извлечения данных в temp, сортировка temp, и затем выдача данных. То есть, сортировка без индекса (по тем же столбцам, что и индекс) будет чуть быстрее, чем создание индекса, т. к. отсутствует фаза переноса данных из temp в базу данных (создание индекса). Например, если создание первичного ключа по NEW_ORDER занимает 23 минуты, а select count(*) по NEW_ORDER занимает 20 минут, то однозначно время выполнения запроса (при отсутствии ПК или других индексов по этим столбцам)
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------
Prepare time = 0ms
Execute time = 13m 4s 718ms
Avg fetch time = 784 718.00 ms
Current memory = 272 268 532
Max memory = 272 514 048
Memory buffers = 16 384
Reads from disk to cache = 2 332 583
Writes from cache to disk = 0
Fetches from cache = 119 977 902
select no_w_id, no_d_id, no_o_id
from new_order
order by no_w_id, no_d_id, no_o_id
будет между 20 и 23 минутами.order by no_w_id, no_d_id, no_o_id
Кроме того, по большим сортировкам с индексами и без есть достаточно подробный материал. Впрочем, можете прислать интересующий вас запрос, попробуем выполнить.
Резюме
Несмотря на "десктопность" компьютера и размер базы данных, тест прошел удачно, и по всем параметрам производительность вполне нормальная. Для Firebird терабайтная база данных не хуже и не лучше 1, 10 или 250 гигабайтной. Разумеется, для нормальной работы с такими объемами требуется более мощная дисковая подсистема, процессор бы неплохо побыстрее, и как минимум 4-х ядерный, и, наконец, 64-разрядная операционная система и сам Firebird.Вопросы и пожелания присылайте на terabyte@ib-aid.com и support@ibase.ru.
P.S. При проверке баз сравнимого размера (500 гиг и выше) gfix может выдавать в лог firebird сообщения
bugcheck during scan of table nnn (table_name)
и
Index n is corrupt (missing entries) in table table_name
На это не стоит обращать внимания, это баг gfix (CORE-3916), исправлено (исправления будут доступны, возможно, в 2.5.2 или выше).