 En
EnФрагментация (или разрежение) таблиц блобами
kdv, ibase.ru, 22.03.2006, последнее обновление – 16.05.2013
IBAnalyst по вашей базе данных может выдать диагностику, что "некоторые таблицы фрагментированы блобами". Что это означает? В справке к IBAnalyst есть описание этой проблемы (F1, содержание, раздел "дополнительные вопросы и ответы", пункт 5). Это описание можно частично продублировать здесь:
Сервер (Firebird или InterBase) сохраняет blob-ы в базе данных тремя способами:
- Level 0 – если содержимое blob помещается на странице данных (достаточно свободного места), то blob будет сохранен на странице данных (той же, где запись, или другой). Например, на страницу размером 4096 байт поместится блоб размером до 4052 байт.
- Level 1 – если содержимое blob не помещается на странице данных, то распределяется новая страница, куда кладется только blob. При этом в записи (в идентификаторе blob) содержится ссылка на эту страницу. В этом случае разрежение записей блобами также может случиться, если количество ссылок на страницы с blob достаточно большое.
- Level 2 – если в случае 2 blob не поместился на одной странице, то отдельно от записи на странице данных создается список ссылок на все страницы данного blob (Если таких страниц много, то создается блоб-страница, содержащая ссылки на страницы с данными блоба, а на странице данных остается ссылка на "списочную" блоб-страницу, т. е. возникает древовидная структура).
Например, если размер страницы базы данных 4K, а в записи сохраняется блоб с размером ~5K, то блоб будет сохранен на отдельной странице. Если же размер blob ~3.5К или меньше, то он с максимальной вероятностью попадет на страницу данных вместе с записью, которой он принадлежит (если на странице есть свободное место).
Для случая 2, блобы, заведомо большие размера страницы, точно так же могут "фрагментировать" страницы данных. Например, для страницы 4к блоб размером 4мб будет иметь 1013 ссылок на страницы с содержимым блоба, и эти ссылки как раз будут занимать 4052 байта, т. е. почти всю страницу данных.
Примечание. Не бывает ситуаций, когда часть блоба находится на странице с записями, а часть – на отдельной для blob странице.
Тест
Для иллюстрации проблемы разрежения записей блобами (которая существует для всех версий InterBase, Firebird и Yaffil) был подготовлен специальный тест. В базе данных с размером страницы 8 килобайт было создано 4 таблицы по 100 тысяч записей- A – со столбцами int и varchar, без blob
- B – то же самое, плюс blob, заполняется данными от 128 до 1024 байт (до 1/8 страницы)
- C – то же самое, blob заполняется данными 1024 байта (1/8 страницы)
- D – то же самое, blob заполняется данными 9000 байт (больше размера страницы 8К).
Материалы к тесту – статистика БД для IBAnalyst (blobtest.txt), запросы с результатами выполнения (blobtest.sql), скрипт создания БД (blobtest.ddl) с таблицами и процедурами (для наполнения данных до 100К записей необходимо выполнить соответствующие процедуры нужное число раз. Результирующий размер БД при 100к записей будет около 1 гигабайта – это минимум для определения разницы в производительности на простейших запросах).
В результате в IBAnalyst мы видим следующую картину:
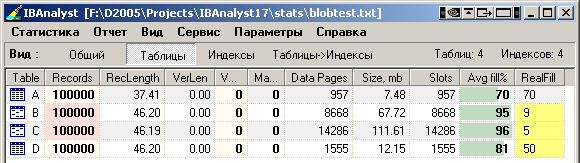
Расшифровка процента заполнения страниц спрятана, т. к. в данном тесте все страницы таблиц заполнены практически на 80-100%. Полную статистику этой БД вы можете взять тут.
Внимание! Информация по блобам в статистике (gstat, IBAnalyst) не выводится до версий Firebird 3.0 и InterBase XE3.
Итак, какие выводы можно сделать из полученной информации:
- Средний размер записи примерно одинаков. Можно было бы в таблицу A добавить blob и не заполнять его данными, но, по крайней мере, видно, что в записи blob занимает примерно 9 байт – так и есть, blob в записи представляет собой ссылку на данные blob, хранимые отдельно от записи (на той же странице данных, или на отдельной).
К сожалению, все версии InterBase и Firebird (вплоть до XE3 и 2.5.x) не показывают ни размер блоба, попавшего на страницу с данными (размер записи не зависит от размера такого блоба), ни количество отдельных страниц, занимаемых блобами. - В случае таблиц B и C, статистика показывает реальное число страниц, занятых как блобами так и записями. Обратите внимание на столбец RealFill – он показывает "вычисляемое" заполнение страниц, как Data_Pages/(размер_записи+заголовок_записи) * число_записей. То есть, блобы совершенно явно находятся на страницах данных, и записями (без блобов) заполнено только 9% (и 5% соответственно) от общего числа занятых таблицами B и C страниц. IBAnalyst для этих таблиц выдает предупреждение (столбец Records помечен розовым цветом), даже если у него нет информации о структуре таблиц (если статистика взята от gstat). Также IBAnalyst хинтом показывает, сколько могло бы быть записей на странице данных, если бы на них не было блобов.
- В таблице D блобы не попали на страницы данных. Это видно по числу страниц, занятых таблицей D. Однако, статистика не показывает, что на самом деле размер этой таблицы много больше, если считать суммарно записи и блобы. Это, конечно, недостаток gstat – если вы умножите 9 тысяч байт на 100 тысяч записей, вы получите общий объем, занятый блобами, равный ~860 мегабайт. А в статистике показывается только объем записей, который составляет 12 мегабайт (что не сильно далеко от размера таблицы, не содержащей блобов вообще – 7.5 мегабайт. Разница в 4.5 мегабайт – это объем ссылок на blob).
- Фрагментированность (разреженность записей) страниц таблиц A и D нормальная, на уровне 50-80%, то есть, на страницах данных достаточно места для создания новых версий записей.
- Фрагментированность страниц таблиц B и C минимальная, на уровне 95%, то есть, на страницах данных остается очень мало места для создания новых версий записей – если обновлять такую таблицу, то для новых версий будут выделяться новые страницы, что плохо в смысле дискового ввода/вывода.
Примечание. "фрагментированность" или "разреженность" записей не относится к размещению одной записи на нескольких страницах (record fragments). Здесь имеется в виду размещение конкретного числа записей на большем числе страниц данных, чем это нужно для их хранения. Грубо говоря, при фрагментации таблиц блобами страницы данных заполнены так – запись-блоб-запись-блоб-запись... Разумеется, "фрагментированность" таблиц может увеличиваться и без блобов, если в результате удаления записей на страницах данных остается много пустых мест (разумеется, после сборки мусора). При этом, пустое место на страницах данных будет использовано при последующей вставке, обновлении или удалении записей. В случае blob он не является "пустым местом".
Теперь, для оценки влияния "разреживания" данных блобами, необходимо выполнить запросы. Я выполнял простейший
select id, name from
специально без выборки блоб-столбца, по 2 раза (для наполнения кэша). Использовался Firebird 1.5.2, размер кэша 2048 (по умолчанию). Результаты 2-го выполнения приведены в таблице:| Execute Time | Reads from disk to cache | Fetches from cache | |
|---|---|---|---|
| A | 1.763 | 0 | 201971 |
| B | 2.073 | 8705 | 217409 |
| C | 2.243 | 14326 | 228648 |
| D | 1.832 | 0 | 203179 |
Здесь видно, что даже на таком элементарном запросе разреженность записей влияет как на скорость выполнения запроса, так и на число чтений с диска. Поскольку Fetches from cache почти идентично у всех 4-х запросов, это означает, что чтение с диска 8 и 14 тысяч страниц как бы "лишнее", но разумеется вынужденное, т. к. в таблицах B и C записи разрежены блобами (обращение к блобу из приложения (не в SQL) возможно только после вычитывания записи, и отдельным вызовом API. Поэтому Fetches не содержит таких дополнительных обращений).
Хотя разницу в скорости запросов можно считать микроскопической, нужно учитывать, что тест проводился в однопользовательском режиме, и на относительно небольшом объеме данных. В многопользовательском режиме, при конкурентных обращениях к страницам данных, "размазанность" данных по таблицам будет сильно ухудшать производительность в реальных запросах.
Причина замедления – в вытеснении кэша. Например, если страницы заполнены блобами на 90%, то получается, что при чтении только записей происходит в 10 раз больше чтений страниц, если бы блобов в этих записях не было. А значит, эти страницы имеют больше шансов выпасть из кэша, и регулярные обращения к этой таблице будут снова и снова приводить к чтению страниц с диска, а не из кэша.
Тест, проведенный на другой таблице, размером 28 гигабайт, с 95 % разрежением записей блобами (записей всего 1.4 гигабайт) показал замедление обычных операций с выборкой данных из этой таблицы на 22 %, опять же, в однопользовательском режиме.
Причина замедления – в вытеснении кэша. Например, если страницы заполнены блобами на 90%, то получается, что при чтении только записей происходит в 10 раз больше чтений страниц, если бы блобов в этих записях не было. А значит, эти страницы имеют больше шансов выпасть из кэша, и регулярные обращения к этой таблице будут снова и снова приводить к чтению страниц с диска, а не из кэша.
Тест, проведенный на другой таблице, размером 28 гигабайт, с 95 % разрежением записей блобами (записей всего 1.4 гигабайт) показал замедление обычных операций с выборкой данных из этой таблицы на 22 %, опять же, в однопользовательском режиме.
Разумеется, если выбирать столбец blob, или даже явно поочередно считывать запись и ее blob, то размещение blob на страницах данных более выгодно, чем размещение blob на отдельных страницах – вместо чтения страницы записей + страниц с блобами, выполняется чтение страниц данных, где находятся и записи, и blob.
Но эта "выгода" проявляется весьма редко. Чаще ухудшение производительности при размещении blob на страницах данных проявляется более явно, чем в этом примитивном примере – достаточно представить себе join или более сложный запрос (включая агрегаты) с такой таблицей, чтобы оценить вред, приносимый излишними чтениями страниц.
Примечание. Разница в скорости выполнения запросов будет куда более заметной, если вы попробуете выполнить select count(id) по этим таблицам, или другой запрос с агрегатными операциями.
Что делать?
Для начала нужно выяснить, действительно-ли разреживание страниц данных блобами влияет на производительность в вашем конкретном случае. Наверное, не стоит беспокоиться, если число записей в таблице невелико (может быть на уровне 10 тысяч и меньше?), или обращения к такой таблице редки, или записи всегда выбираются одновременно с блобами.В остальных случаях – да, беспокоиться стоит. Данные в blob обычно "второстепенны", и решить данную проблему можно, создав еще одну таблицу (связь 1-1) со столбцом первичного ключа исходной таблицы и блоб-столбцами. Здесь уже будет не важно, разреживаются ли данные блобами в этой дополнительной таблице, или нет. Это, конечно, усложнит запросы, которые выбирают и данные и blob. Во всех остальных случаях, когда к столбцам blob обращений нет, запросы останутся неизменными, а скорость их выполнения улучшится.
Изменение размера страницы
При restore вы можете указать новый размер страницы для базы данных (см. ключи командной строки gbak). Это может привести к двум противоположным результатам:
-
если новый размер страницы меньше, те блобы, которые попадали на страницы, будут храниться отдельно, и разреженность записей существенно снизится.
-
если новый размер страницы больше, те блобы, которые не попадали на страницы данных, будут теперь храниться на них, что увеличит разреженность записей.
Пока что, при наличии большого количества таблиц с blob следует выбрать оптимиальный размер страницы БД и не делать restore с большим размером страницы.
Однако, не рекомендуется из-за данной проблемы уменьшать размер страницы БД, т. к. это также ухудшит производительность в отношении таблиц без blob, и может увеличить глубину индексов.
Примечание. IBExpert и аналогичные инструменты, производящие backup/restore посредством Services API, как правило, не имеют возможности не указывать размер страницы при restore. Это означает, что вы каждый раз при restore вручную (средствами IBExpert) должны указывать размер страницы, пусть даже тот же, который был установлен вами при создании БД или предыдущем restore (gbak при restore восстанавливает БД с тем размером страницы, который у нее был при backup, если не указывать новый размер страницы). Весьма велик шанс, что вы ошибетесь, и поменяете размер страницы на новый.
Есть еще один случай, когда при restore даже с тем же размером страницы может возникнуть разреженность записей – если таблица существует, и вы "на ходу" добавили столбец blob и заполнили его данными, которые по размеру могут попасть на страницы данных рядом с записями (если blob меньше текущего размера страницы). Здесь, при достаточно плотном размещении данных blob не имеют шансов попасть на страницы с записями, и поэтому будут размещены на отдельных страницах. Но при restore записи будут восстановлены вместе с блобами, то есть подряд, на одни и те же страницы данных (потому что при backup данные будут именно так и записаны в бэкап – запись-блоб-запись-блоб и т. д.).Также не рекомендуется пытаться решить проблему "фрагментации" заменой столбца blob на столбец varchar. Столбцы varchar всегда хранятся вместе с записью, таким образом, записи не просто будут "фрагментированы" как в случае blob, но и будут состоять из фрагментов (1 запись на 2-х и более страницах, если в сумме размер записи превысит размер страницы).
P.S. Возможно, я уделил слишком много внимания этой проблеме, однако, с учетом среднего объема нынешних баз данных Firebird и InterBase в десятки и сотни гигабайт, кому-то эта статья поможет улучшить производительность своих баз данных и приложений.